DBScan Clustering Algorithm
Exploring Density-Based Spatial Clustering with DBSCAN
 Program output
Program outputDBSCAN Clustering Algorithm
This README file provides information on the DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm and its implementation. DBSCAN is a density-based clustering algorithm that groups together data points that are close to each other in dense regions and identifies outliers as points in low-density regions. Below is a breakdown of the content covered in this README.
Table of Contents
- Part A: DBSCAN Clustering Algorithm
- Part B: Implementing DBSCAN
- Part C: Handling Outliers
- Part D: Exploring Different Parameters
- Part E: DBSCAN on Circular Dataset
- Part F: DBSCAN on Moon-shaped Dataset
- Part G: DBSCAN on Diabetes Dataset
Part A: DBSCAN Clustering Algorithm
In this section, the DBSCAN algorithm is introduced. The make_blobs function from sklearn.datasets is used to generate a synthetic dataset for demonstration purposes.
Part B: Implementing DBSCAN
The DBSCAN algorithm is implemented using the DBSCAN class from sklearn.cluster. The eps (epsilon) and min_samples parameters are set to define the clustering behavior.
Part C: Handling Outliers
This section discusses how DBSCAN identifies outliers as noise points. The outliers are plotted separately to visualize their presence in the dataset.
Part D: Exploring Different Parameters
The impact of changing the eps and min_samples parameters on the DBSCAN algorithm is explored. The dataset is visualized with different parameter values to observe the clustering behavior and outlier detection.
Part E: DBSCAN on Circular Dataset
DBSCAN is applied to a circular dataset generated using the make_circles function from sklearn.datasets. The resulting clusters are visualized with different colors.
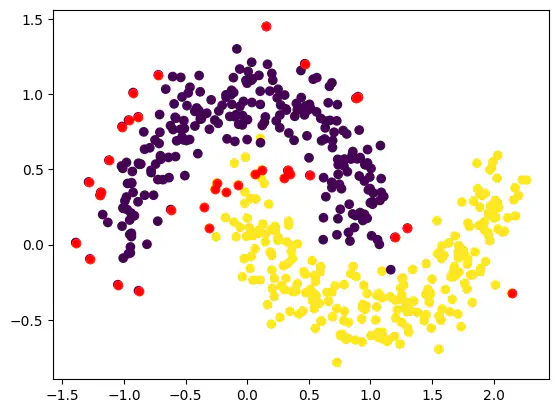
Part F: DBSCAN on Moon-shaped Dataset
DBSCAN is applied to a moon-shaped dataset generated using the make_moons function from sklearn.datasets. The resulting clusters are visualized with different colors.
Part G: DBSCAN on Diabetes Dataset
The DBSCAN algorithm is applied to the diabetes dataset. The steps performed in the previous sections are repeated on this dataset, showcasing how DBSCAN can be used in a real-world scenario.
In this README, you will find code examples, visualizations, and explanations of the DBSCAN algorithm and its application to different datasets. Follow the provided instructions and explore the implementation of DBSCAN for clustering and outlier detection purposes.
# import libraries
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
DBScan Clustering Algorithm
from sklearn.datasets import make_blobs
# Generating the dataset
# Classes denote the labels here:
dataset, classes = make_blobs(n_samples = 250, n_features = 2, centers = 1, cluster_std = 0.3, random_state = 1)
# Dataset:
plt.scatter(dataset[:, 0], dataset[:, 1])
<matplotlib.collections.PathCollection at 0x7f3fa21fa7f0>
classes
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0])
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps = 0.3, min_samples = 20) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(dataset)
pred
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
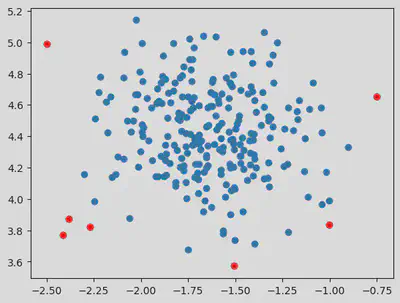
# Plot the data points of the cluster and show the outliers(those with 1 value):
# Sample Number of Outliers:
outlier_index = np.where(pred == -1)
# Value of the outlier:
outlier_val = dataset[outlier_index]
print("Outlier Index : \n", outlier_index, "\nOutlier Value : \n", outlier_val)
Outlier Index :
(array([ 20, 41, 56, 92, 154, 190, 202]),)
Outlier Value :
[[-0.75030277 4.65386526]
[-2.4114921 3.77224069]
[-2.38361081 3.87321996]
[-1.00234999 3.83758159]
[-2.27072027 3.82371311]
[-2.49748541 4.98774851]
[-1.50503782 3.57172953]]
plt.scatter(dataset[:, 0], dataset[:, 1])
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3fa218baf0>
On Changing the Eps value and min samples
dbscan = DBSCAN(eps = 0.1, min_samples = 5) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(dataset)
# Sample Number of Outliers:
outlier_index = np.where(pred == -1)
# Value of the outlier:
outlier_val = dataset[outlier_index]
plt.scatter(dataset[:, 0], dataset[:, 1])
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3fa2271640>
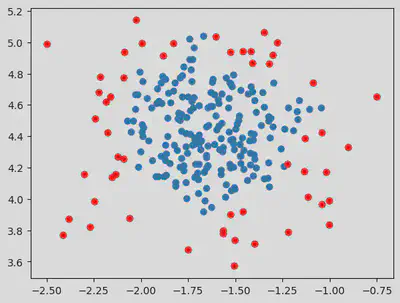
Hence from the above values, we see that taking eps value of 0.5 and above helps in eliminating outliers.
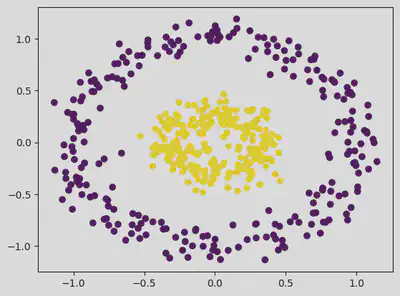
from sklearn.datasets import make_circles
dataset, classes = make_circles(n_samples = 500, factor = 0.3, noise = 0.1)
plt.scatter(dataset[:, 0], dataset[:, 1], c = classes) # c = classes gives different colours to the clusters
<matplotlib.collections.PathCollection at 0x7f3fa057a880>
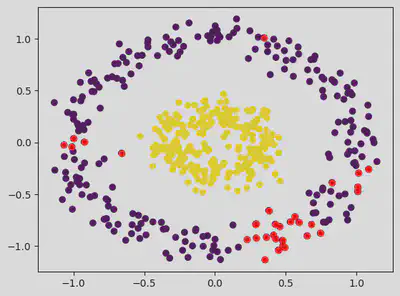
dbscan = DBSCAN(eps = 0.2, min_samples = 15) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(dataset)
# Sample Number of Outliers:
outlier_index = np.where(pred == -1)
# Value of the outlier:
outlier_val = dataset[outlier_index]
plt.scatter(dataset[:, 0], dataset[:, 1], c = classes)
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3fa04f4580>
pred
array([ 0, 0, 2, 2, 0, 8, 1, 0, 0, 0, 4, 8, 2, 0, 5, 0, 9,
1, 0, 0, 0, 0, 1, 0, 9, 0, 1, 0, 0, 0, 0, 0, 0, 7,
0, 1, 6, 0, 6, 0, -1, 2, 9, 3, 4, 2, 0, 8, 0, 0, 1,
0, 2, 0, 0, 0, 0, 5, 1, 0, 0, 0, 4, 4, 5, 10, -1, 4,
6, 0, 2, 0, -1, 6, 0, 0, 2, 3, 0, 0, 0, 5, 9, 0, 0,
7, 0, 0, 6, 0, 2, 0, 2, 0, 9, 1, 0, 0, 4, 1, 10, 6,
0, 2, 0, 1, 0, 0, 5, 4, 7, 0, 0, -1, 2, 0, 3, 1, 5,
2, 0, 0, 0, 0, 0, 7, 6, 4, 0, 0, 8, 0, 0, 0, 4, 0,
0, 0, 7, 0, 0, 0, 2, 4, 8, 0, 0, 0, -1, 9, 10, 2, 0,
1, 0, 0, -1, 0, -1, 1, 2, 0, 0, 8, 0, 0, 1, 0, 2, 0,
0, 0, 10, 8, 0, 8, 0, -1, 0, 0, 9, 10, -1, 0, -1, 2, 0,
0, 0, 0, 6, 0, 7, 8, 3, 0, 0, 0, 0, 0, 0, 2, 10, 0,
0, -1, 0, 3, 2, 0, 0, 0, 2, 8, 0, 0, 4, 0, 10, 0, 8,
6, 9, -1, 7, -1, 0, 0, 2, 0, 9, 8, 0, 0, 0, 0, 0, 0,
3, 0, 0, 0, 6, 0, 9, 0, 0, 0, 0, 1, 8, 8, 0, 0, 0,
3, 0, 0, 4, 0, 9, 0, 0, 0, 0, 2, 0, 0, 4, 1, 4, 0,
-1, 0, 0, 1, 10, 0, 0, 6, 2, 4, 3, 4, 0, -1, 0, -1, 0,
0, 0, 0, 5, 6, 4, 0, 0, 10, 0, -1, -1, 0, 7, 9, 4, 8,
10, 0, 10, 0, 0, 7, 5, 8, 0, 6, 5, 0, 10, 6, 2, 3, 5,
8, 0, 0, 0, 8, 0, 8, 0, 0, -1, 0, 0, 0, 6, 2, 1, 0,
0, 6, 0, 1, 2, 10, 9, 2, 0, 3, 7, 0, 0, 0, 0, 2, 0,
9, 0, 1, 0, 8, 2, 1, 0, 0, 0, 0, 0, 2, 0, 0, 0, 9,
9, 2, 0, 0, 0, 0, 0, 0, 4, 8, 10, -1, 9, 3, 2, 4, 9,
-1, 0, 0, -1, 0, 0, -1, 2, -1, 0, 0, 0, 0, 0, 0, 9, 1,
-1, 0, 0, -1, -1, 2, -1, 0, 0, 0, 0, 10, 0, 0, 3, 0, 8,
-1, 0, -1, 0, 8, 3, 2, 1, 8, 0, 0, 0, 6, 0, 0, 4, 0,
7, -1, 0, 0, 0, 3, 5, 0, -1, 1, 2, 10, 2, 5, 0, 0, 4,
8, 6, 7, 0, 0, 6, 0, 6, 0, 6, 0, 10, 2, 0, 0, 0, 5,
0, 0, 0, 1, 0, 0, 6, 0, 0, 1, 7, 5, 0, 0, 6, 5, 4,
6, 4, 0, 0, 7, 0, 3])
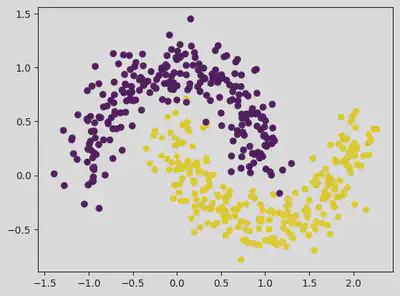
from sklearn.datasets import make_moons
dataset, classes = make_moons(n_samples = 500, random_state = 1, noise = 0.15)
plt.scatter(dataset[:, 0], dataset[:, 1], c = classes) # c = classes gives different colours to the clusters
<matplotlib.collections.PathCollection at 0x7f3fa0455f10>
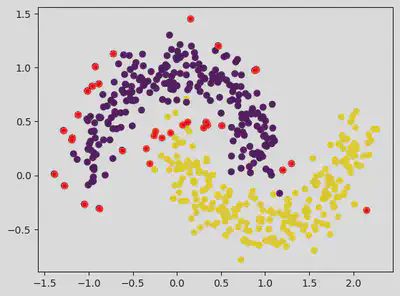
dbscan = DBSCAN(eps = 0.2, min_samples = 15) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(dataset)
# Sample Number of Outliers:
outlier_index = np.where(pred == -1)
# Value of the outlier:
outlier_val = dataset[outlier_index]
plt.scatter(dataset[:, 0], dataset[:, 1], c = classes)
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3fa22f0c10>
On Changing the Eps value and min samples
dbscan = DBSCAN(eps = 0.3, min_samples = 15) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(dataset)
# Sample Number of Outliers:
outlier_index = np.where(pred == -1)
# Value of the outlier:
outlier_val = dataset[outlier_index]
plt.scatter(dataset[:, 0], dataset[:, 1], c = classes)
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3f9ffab9a0>
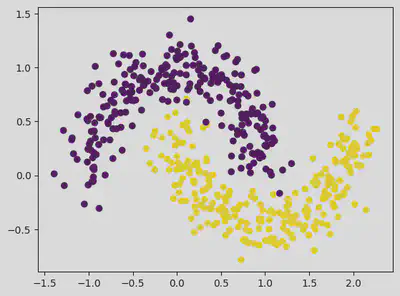
Hence from the above values, we see that taking eps value of 0.3 and above helps in eliminating outliers.
On increasing the number of samples, outliers seem to increase.
Loading the dataset:
df = pd.read_csv("/content/diabetes.csv")
df
| Glucose | BMI | Outcome | |
|---|---|---|---|
| 0 | 148 | 33.6 | 1 |
| 1 | 85 | 26.6 | 0 |
| 2 | 183 | 23.3 | 1 |
| 3 | 89 | 28.1 | 0 |
| 4 | 137 | 43.1 | 1 |
| ... | ... | ... | ... |
| 763 | 101 | 32.9 | 0 |
| 764 | 122 | 36.8 | 0 |
| 765 | 121 | 26.2 | 0 |
| 766 | 126 | 30.1 | 1 |
| 767 | 93 | 30.4 | 0 |
768 rows × 3 columns
<script>
const buttonEl =
document.querySelector('#df-633213a4-5b73-49c1-af8c-02b29db5f3f6 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-633213a4-5b73-49c1-af8c-02b29db5f3f6');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
EDA:
df.head()
| Glucose | BMI | Outcome | |
|---|---|---|---|
| 0 | 148 | 33.6 | 1 |
| 1 | 85 | 26.6 | 0 |
| 2 | 183 | 23.3 | 1 |
| 3 | 89 | 28.1 | 0 |
| 4 | 137 | 43.1 | 1 |
<script>
const buttonEl =
document.querySelector('#df-5cefb7b3-8099-4c43-9c9a-0020b9880abb button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-5cefb7b3-8099-4c43-9c9a-0020b9880abb');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Glucose 768 non-null int64
1 BMI 768 non-null float64
2 Outcome 768 non-null int64
dtypes: float64(1), int64(2)
memory usage: 18.1 KB
df.shape
(768, 3)
df.describe()
| Glucose | BMI | Outcome | |
|---|---|---|---|
| count | 768.000000 | 768.000000 | 768.000000 |
| mean | 120.894531 | 31.992578 | 0.348958 |
| std | 31.972618 | 7.884160 | 0.476951 |
| min | 0.000000 | 0.000000 | 0.000000 |
| 25% | 99.000000 | 27.300000 | 0.000000 |
| 50% | 117.000000 | 32.000000 | 0.000000 |
| 75% | 140.250000 | 36.600000 | 1.000000 |
| max | 199.000000 | 67.100000 | 1.000000 |
<script>
const buttonEl =
document.querySelector('#df-c7b13b05-315d-4802-ad90-5d29f753a613 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-c7b13b05-315d-4802-ad90-5d29f753a613');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
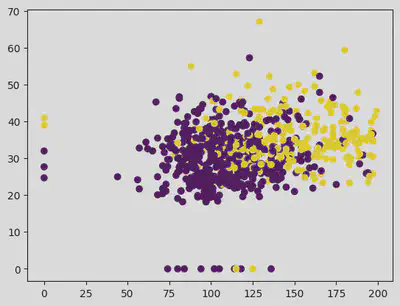
Dropping the outcome column as we are building an unsupervised model. So outcome is not required.
X = df.drop(['Outcome'], axis=1)
plt.scatter(X["Glucose"], X["BMI"], c = df["Outcome"])
<matplotlib.collections.PathCollection at 0x7f3f9fbaf970>
dbscan = DBSCAN(eps = 4, min_samples = 6) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(X)
pred
array([ 0, 0, -1, 0, 0, 0, 0, 0, -1, -1, 0, 0, 0, 0, -1, 0, 0,
0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, -1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, -1, 0, 0, 0, 0, -1,
0, 0, 0, 0, 0, 0, 0, -1, -1, 0, 0, 0, 0, -1, 0, 0, -1,
0, 0, 0, 0, 0, -1, 0, -1, 0, 0, 0, 0, -1, 0, -1, -1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, -1, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1, 0, 0, 0, 0, 0, 0,
0, -1, -1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -1, 0, 0, 0, -1, 0, 0, 0, 0, -1, 0, 0, 2, 0,
0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 2, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, -1, 2, 0, 0, -1, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0,
0, 0, -1, 0, 0, 0, 0, 0, 0, -1, 0, 0, -1, 0, 0, 0, 0,
0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0,
0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
-1, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
-1, 1, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0,
0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -1, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, -1, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, -1, 0, 0, 0,
0, -1, 0, 0, 0, -1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, -1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0,
0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
-1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1, 0, 0, 0, 0,
0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
-1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1, 0, 0, 0, 0, 0, 0,
-1, -1, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0,
0, 1, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0])
plt.scatter(X["Glucose"], X["BMI"], c = pred)
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3f9f7de220>
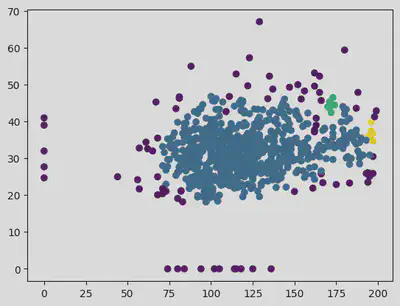
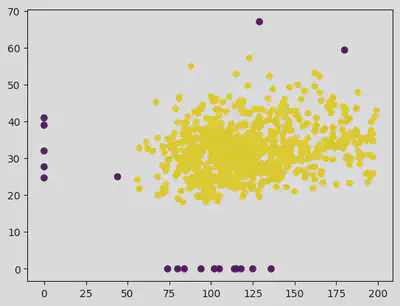
Hence for eps value of 14 and samples as 25 helps in getting a clear distinction in the clusters.
dbscan = DBSCAN(eps = 14, min_samples = 25) # Epsilon default value = 0.5.
pred = dbscan.fit_predict(X)
plt.scatter(X["Glucose"], X["BMI"], c = pred)
plt.scatter(outlier_val[:, 0], outlier_val[:, 1], color = 'r')
<matplotlib.collections.PathCollection at 0x7f3f9f764820>
Srihari Thyagarajan
B Tech AI Senior Student
Hi, I’m Haleshot, a senior-year student studying B Tech Artificial Intelligence. I like projects relating to ML, AI, DL, CV, NLP, Image Processing, etc. Currently exploring Python, FastAPI, projects involving AI and platforms such as HuggingFace and Kaggle.