Text Preprocessing with NLTK
Level One Text Preprocessing Operations
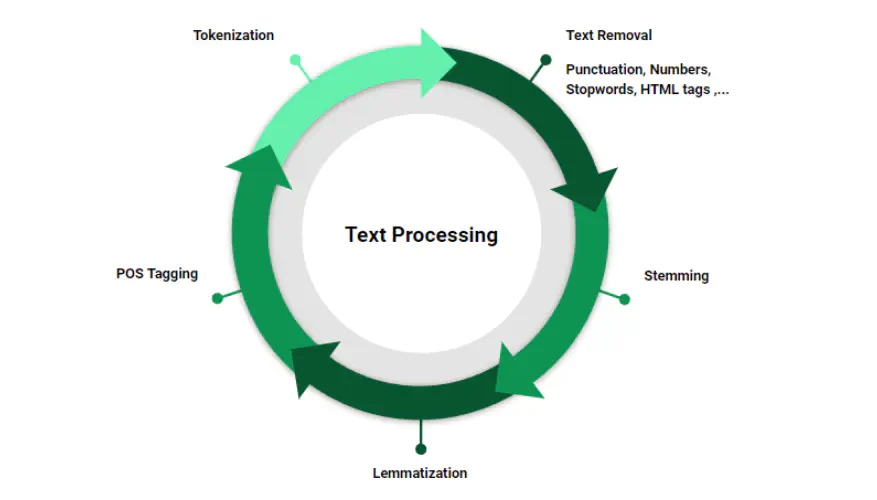 Photo Caption: Aysel Aiden - Medium
Photo Caption: Aysel Aiden - MediumNatural Language Processing
Table of Contents
Aim
Text Preprocessing level one operations
- To implement operations such as change of case, sentence tokenization, word tokenization, stop word removal, punctuation mark removal, stemming, lemmatization, Parts of Speech (PoS) tagging using NLTK (Natural Language Tool Kit) platform
- To implement tokenization without using built-in function of NLTK
- To comprehend the difference between stemming and lemmatization
- To count frequency of each word in the given document
Prerequisite
- Python
Outcome
After successful completion of this experiment students will be able to understand basic concepts of text processing.
Theory
Natural Language Processing (NLP) is a branch of Data Science which deals with text data. Apart from numerical data, text data is available extensively and is used to analyze and solve business problems. However, before using the data for analysis or prediction, processing the data is important.
To prepare the text data for model building, text preprocessing is the very first step in NLP projects. Some of the preprocessing steps include:
- Removing punctuations like . , ! $( ) * % @
- Removing URLs
- Removing stop words
- Lowercasing
- Tokenization
- Stemming
- Lemmatization
- Part-of-Speech Tagging
Steps to clean the data
Punctuation Removal: In this step, all the punctuations from the text are removed. The
stringlibrary in Python contains some pre-defined lists of punctuations.Lowering the Text: It is a common preprocessing step where the text is converted into the same case, preferably lower case. However, lowercasing can lead to loss of information in some NLP problems.
Tokenization: The text is split into smaller units. Sentence tokenization or word tokenization can be used based on the problem statement.
Stop Word Removal: Stop words are commonly used words that carry less or no meaning. NLTK library provides a list of stop words for the English language.
Stemming: It reduces words to their root/base form. However, stemming may result in words losing their meaning or not being reduced to proper English words.
Lemmatization: It reduces words to their base form while preserving their meaning using a pre-defined dictionary.
Part-of-Speech Tagging: Tags are assigned to words defining their main context, functions, and usage in a sentence.
Task to be Completed in PART B
A.5 Task
- To implement operations such as change of case, sentence tokenization, word tokenization, stop word removal, punctuation mark removal, stemming, lemmatization, Parts of Speech (PoS) tagging using NLTK (Natural Language Tool Kit) platform
- To implement tokenization without using built-in function of NLTK
- To comprehend the difference between stemming and lemmatization
- To count frequency of each word in the given document
# import libraries used
import nltk
from nltk import sent_tokenize, word_tokenize, RegexpTokenizer, pos_tag
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer, WordNetLemmatizer
import pandas as pd
from nltk.probability import FreqDist
Tasks
a. To implement operations such as:
Change of case, sentence tokenization, word tokenization, stop word removal, punctuation mark removal, stemming, lemmatization, Parts of Speech (PoS) tagging using NLTK (Natural Language Tool Kit) platform
Change of case:
a = 'This iS a TeXt'
# Text is not uniform since it has characters with varied cases
# and hence should be converted to uniform case (in this case Lower case)
# for conducting operations on it.
a = a.lower()
print(a)
this is a text
Sentence tokenization
sentence = "This is a demo text used for testing the various built in methods of nltk library. This is a new sentence."
print(sent_tokenize(sentence))
['This is a demo text used for testing the various built in methods of nltk library.', 'This is a new sentence.']
Word Tokenization
sentence = "This is a demo text used for testing the various built in methods of nltk library"
print(word_tokenize(sentence))
['This', 'is', 'a', 'demo', 'text', 'used', 'for', 'testing', 'the', 'various', 'built', 'in', 'methods', 'of', 'nltk', 'library']
import nltk
nltk.download('averaged_perceptron_tagger')
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\leosr\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
True
Stop Word Removal
stopword = stopwords.words('english')
text = "This is a demo text used for testing the various built in methods of nltk library"
word_tokens = nltk.word_tokenize(text)
removing_stopwords = [word for word in word_tokens if word not in stopword]
print (removing_stopwords)
['This', 'demo', 'text', 'used', 'testing', 'various', 'built', 'methods', 'nltk', 'library']
Punctuation mark Removal
text = "This' is' a demo text used for testing the various, doesn't, and, built in methods of nltk library"
# Create a tokenize based on a regular expression.
# "[a-zA-Z0-9]+" captures all alphanumeric characters
tokenizer = RegexpTokenizer(r"[a-zA-Z0-9]+")
# Tokenize str1
words1 = tokenizer.tokenize(text)
print(words1)
['This', 'is', 'a', 'demo', 'text', 'used', 'for', 'testing', 'the', 'various', 'doesn', 't', 'and', 'built', 'in', 'methods', 'of', 'nltk', 'library']
Stemming
porter = PorterStemmer()
print(porter.stem("play"))
print(porter.stem("playing"))
print(porter.stem("plays"))
print(porter.stem("played"))
play
play
play
play
Lemmatization
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("plays", 'v'))
print(lemmatizer.lemmatize("played", 'v'))
print(lemmatizer.lemmatize("play", 'v'))
print(lemmatizer.lemmatize("playing", 'v'))
play
play
play
play
Part of Speech Tagging (PoS Tagging)
text = "This is a demo text used for testing the various built in methods of nltk library"
tokenized_text = word_tokenize(text)
tags = tokens_tag = pos_tag(tokenized_text)
print(tags)
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('demo', 'NN'), ('text', 'NN'), ('used', 'VBN'), ('for', 'IN'), ('testing', 'VBG'), ('the', 'DT'), ('various', 'JJ'), ('built', 'VBN'), ('in', 'IN'), ('methods', 'NNS'), ('of', 'IN'), ('nltk', 'JJ'), ('library', 'NN')]
b. To implement tokenization without using built in function of nltk.
We take a given text in the form of a sentence and split it using a particular parameter such as comma (,) (which is popular in csv files), or just normal space ( ) which is used in general text format.
# Performing tokenization in a sentence using space as a parameter
text = "This is a demo text used for testing the various built in methods of nltk library"
print(text.split())
print()
# Performing tokenization in a sentence using comma as a parameter
text = "This, is, a demo text ,used for testing, the various built, in methods of nltk library"
print(text.split(","))
['This', 'is', 'a', 'demo', 'text', 'used', 'for', 'testing', 'the', 'various', 'built', 'in', 'methods', 'of', 'nltk', 'library']
['This', ' is', ' a demo text ', 'used for testing', ' the various built', ' in methods of nltk library']
c. To comprehend the difference between stemming and lemmatization
Stemming and lemmatization are both techniques used in Natural Language Processing (NLP) to reduce words to their base form. The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma 12.
In other words, stemming is faster than lemmatization because it just gets the origin or root/base word unlike lemmatization which makes sense for the word 1.
d. To count frequency of each word in the given document (using nltk)
text = "This is a demo text used for testing the various built in methods of nltk library"
wt_words = text.split()
data_analysis = nltk.FreqDist(wt_words)
filter_words = dict([(m, n) for m, n in data_analysis.items()])
for key in sorted(filter_words):
print("%s: %s" % (key, filter_words[key]))
This: 1
a: 1
built: 1
demo: 1
for: 1
in: 1
is: 1
library: 1
methods: 1
nltk: 1
of: 1
testing: 1
text: 1
the: 1
used: 1
various: 1
d. To count frequency of each word in the given document (without using nltk)
d = {}
file = open("textfile.txt", 'r')
for i in file.read().split():
if i in d:
d[i] += 1
else:
d[i] = 1
print(d)
{'To': 1, 'know': 4, 'that': 3, 'we': 4, 'what': 2, 'know,': 2, 'and': 1, 'to': 1, 'do': 2, 'not': 2, 'is': 1, 'true': 1, 'knowledge.': 1}
Srihari Thyagarajan
B Tech AI Senior Student
Hi, I’m Haleshot, a senior-year student studying B Tech Artificial Intelligence. I like projects relating to ML, AI, DL, CV, NLP, Image Processing, etc. Currently exploring Python, FastAPI, projects involving AI and platforms such as HuggingFace and Kaggle.